- 02/04
- 2021
-
QQ扫一扫

-
Vision小助手
(CMVU)
MonoRec,一种半监督的单目密集重建架构,该方案可在动态环境中根据单个移动摄像机预测深度图。MonoRec提出了一种新型的多阶段训练方案,该方案可以不需要LiDAR深度值的半监督损失公式。在KITTI数据集上仔细评估了MonoRec,并表明与多视图和单视图方法相比,它具有最先进的性能。通过在KITTI上训练的模型,我们进一步证明了MonoRec能够很好地推广到牛津RobotCar数据集和手持摄像机记录的更具挑战性的TUM-Mono数据集上
相关工作与主要贡献
多视图立体视觉(MVS)方法基于具有已知姿势的一组图像来估计3D环境的稠密点云。在过去的几年中,基于经典的优化方法已经开发出很多种方案来解决MVS问题。
基于单目的深度预测仅依赖于单个图像,单目深度预测通常在训练期间仍然消耗视频序列或立体图像。它的目的是解决与本文提出的类似的问题,即对包括静态和动态对象的3D场景进行稠密点云重构。
为了结合具有深度的MVS和单目深度预测的优势,我们提出了MonoRec,这是一种新颖的单目密集重建架构,由MaskModule和DepthModule组成。使用成本量对来自多个连续图像的信息进行编码,这些成本量是基于结构相似性指标度量(SSIM)而不是像以前的工作一样基于绝对差之和(SAD)构建的。MaskModule能够识别运动像素并降低成本量中的相应体素。因此,与其他MVS方法相比,MonoRec不受移动物体上的伪影的影响,因此可提供静态和动态物体的准确深度估计。与KITTI数据集上的其他MVS和单目深度预测方法相比,通过提出的多阶段训练方案,MonoRec可以实现最先进的性能。下图显示了该方法生成的密集点云
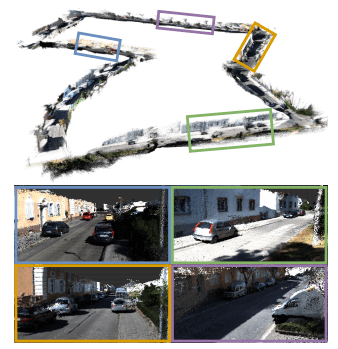
MonoRec可以通过单个移动相机提供了高质量的稠密重建的点云。该图显示了通过简单地累积预测的深度图来进行大规模室外点云重建(KITTI数据集)的示例。
主要内容
MonoRec使用一组连续的图像帧和相应的相机位姿来预测给定关键帧的稠密深度图。MonoRec结构结合了MaskModule和DepthModule。MaskModule预测可提高深度精度的运动对象mask,并允许我们消除3D重建中的噪声。DepthModule根据mask的代价来预测深度图。
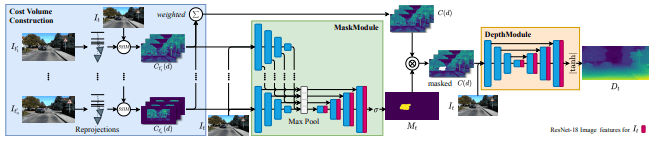
MonoRec架构
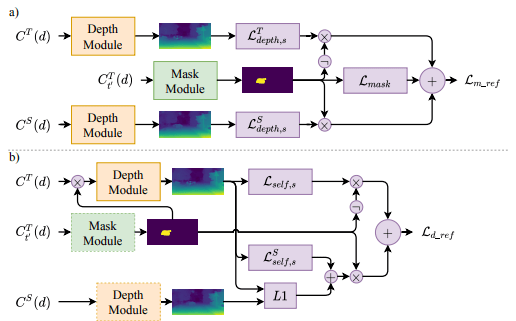
细化损失:a)MaskModule细化和b)DepthModule细化损失函数。
实验对比
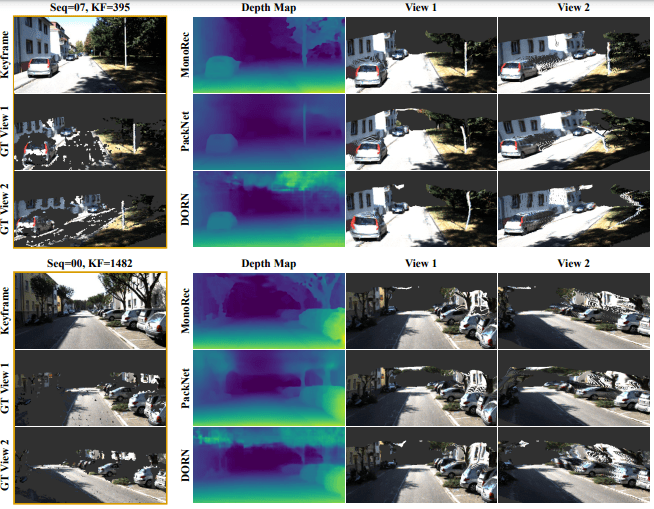

由kitti数据集生成的稠密点云的质量
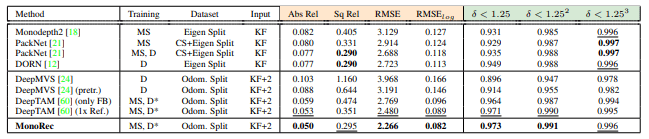
MonoRec与KITTI测试集中的其他方法之间的比较。“数据集”列显示了相应方法使用的训练数据集,评估结果表明,该的方法总体上取得了最佳性能。

运动对象深度估计的比较:与其他MVS方法相比,MonoRec能够预测可能的深度。此外,深度预测在场景的静态区域中具有较少的噪声和伪像
总结
MonoRec,这是一种深度学习架构,仅通过单个移动相机即可估算出精确3D重建后的稠密点云。论文首先建议使用SSIM作为光度测量来构建成本量。为了处理室外场景中常见的动态对象,提出了一种新颖的MaskModule,它可以根据输入成本量预测移动对象mask。使用预测的mask,使用提出的DepthModule能够估计静态和动态对象的准确深度。此外,我们提出了一种新颖的多阶段训练方案以及用于训练深度预测的半监督损失公式。综合起来,MonoRec能够在KITTI上定性和定量地胜过最新的MVS和单目深度预测方法,并且在Oxford Oxford RobotCar和TUM-Mono上表现较好。这种从单个移动摄像机中恢复准确的3D稠密点云的能力将有助于将摄像机确立为智能系统的先导传感器。