- 06/13
- 2022
-
QQ扫一扫

-
Vision小助手
(CMVU)
什么是OCR光学字符识别?
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。衡量一个OCR系统性能好坏的主要指标有:拒识率、误识率、识别速度、用户界面的友好性,产品的稳定性,易用性及可行性等。
在工业领域,光学字符识别 (OCR) 是一项机器视觉任务,包括从图像中提取文本信息。
OCR 最先进的技术提供高精度的文本识别,并且对中等颗粒图形噪声无懈可击。它们还适用于识别使用点阵打印机制作的字符。该技术为部分遮挡或变形的字符提供了令人满意的结果。
识别过程的效率主要取决于文本分割结果的质量。大多数识别案例都可以使用提供的一组识别模型完成。在其他情况下,可以轻松准备新的识别模型。
OCR光学字符识别技术步骤
为了实现最准确的识别,有必要进行仔细的文本提取和分段。从图像获取文本的总体过程包括以下步骤:
从图像中读取文本
获取文本位置 从背景中提取文本 分段文本 使用准备好的OCR模型 字符识别 | |
获取文本位置
文本的位置是固定的,它由称为掩码的框描述。例如,个人身份证是按照正式规范制作的。每个数据字段的位置是已知的。经过良好校准的视觉系统可以拍摄文本位置几乎恒定的图像。

文本位置不是固定的,但它与输入图像上的特征元素或特殊标记(光学标记)相关。要获取文本的位置,必须找到光学标记。这可以通过模板匹配、1D 边缘检测或其他技术完成。
未指定文本的位置,但可以通过图像阈值轻松地从背景中分离字符。然后可以使用 Blob 分析技术找到正确的字符。

从背景中提取文本
文本提取过程中的主要复杂情况可能是光线不均匀。某些技术(如光规范化或边缘锐化)有助于查找字符。

原始图像




经过光规范化处理的不均匀光线图像
此时,已提取的文本区域已准备好进行分段。
分段文本
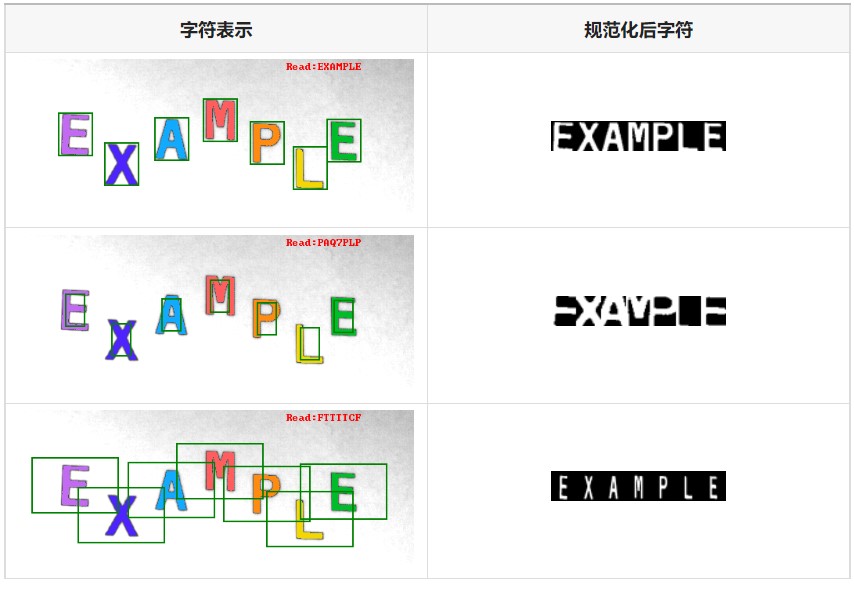
文本区域分割是将区域拆分为行和单个字符的过程。只有当每个区域包含一个字符时,识别才可能实现。

当文本文本行分开时,每行必须拆分为单独的字符。

接下来,提取的字符将从图形表示形式转换为文本表示形式。
调用OCR模型库
通过调用OCR模型库,使识别到的字符以文本形式与模型库进行比对,匹配数据最相似的模板,得出准确的字符信息。
字符识别
通常来说需要选择适当的字符规范大小,来分类字符的大小。
【来源:光虎光学内部培训资料】
光虎光学专业生产由德国设计的工业镜头。
以高精度双远心镜头为核心,涵盖高性能FA定焦镜头、变倍镜头等产品。
如面阵与线扫工业相机、智能相机、3D相机、红外与紫外相机、光源、图像采集卡、机器视觉软件及其他周边产品。
http://www.optiger.com.cn/
- 上一条:固定式和臂上式3D相机的区别
- 下一条:计算成像技术的介绍